Overview
The central part of generative AI tools is the Large Language Model (LLM), a computational machine which predicts the likely continuation of a given input sequence. This continuation is the output.
Foundations in machine learning
The development of LLMs stems from machine learning, where systems improve their performance by encoding patterns extracted from input data rather than being explicitly programmed. More specifically, LLMs are built using deep learning, a subset of machine learning that uses multi-layered structures called neural networks which are made up of interconnected conceptual “neurons”, with every connection assigned a particular strength (known as weight).
The training process
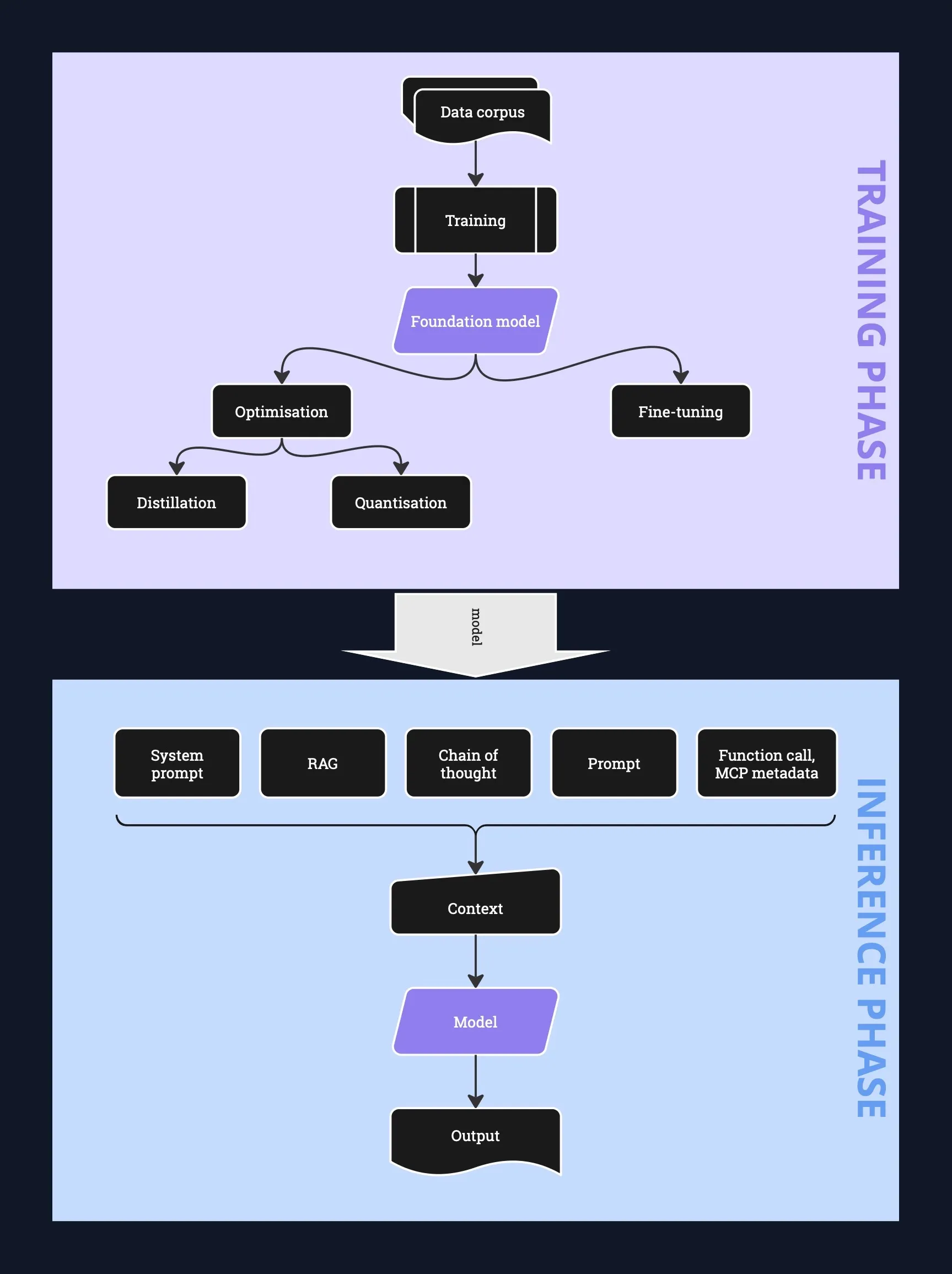
Training a model means processing vast amounts of diverse data (text, images, audio and video) to calculate internal neural network parameters called model weights with the goal of reducing the error in its predictions. Once trained, these models can be used for inference, the phase in which they generate predictions based on new inputs.
The initial result of training is a foundation model, ie. a model that is more general purpose. This model can then be fine-tuned or otherwise adapted to specific tasks. Fine-tuning encompasses a variety of approaches (such as additional training on domain-specific data) with the goal of modifying model weights for better performance on a specific task.
Post-training, the model can also be optimised to reduce computational requirements. The two main ways to achieve that are distillation and quantisation, both of which are lossy in terms of model capability.
Distillation compresses a large model into a smaller one by “teaching” the smaller model to mimic the larger one’s behavior.
Quantisation is a technique that converts model weights to a lower precision representation (eg. from 32-bit floats to 8-bit integers) to save memory and speed up computation.
Additionally, some LLMs employ a MoE (mixture of experts) architecture, where a gating network routes inputs to a collection of specialised models (“experts”) depending on the input. This makes inference faster as it requires computation with fewer parameters (using a single “expert”), but the downside is that the whole model has to be loaded into memory nonetheless.
Tokens and context
LLMs operate on sequences of integers rather than text or pixels. Of course, text and pixels are also sequences of integers but LLMs don’t work directly on, say, Unicode codepoints. Instead, the input is broken down into tokens with numeric indexes. Tokenisation approaches differ between models, but often individual tokens correspond to subword sequences, words, punctuation marks etc. There are two reasons for this approach:
- It effectively reduces the length of the input/output sequences
- It facilitates the operation of models on linguistic structures, which is much more effective for language tasks than operating on characters.
The length of an input sequence an LLM can process is limited and is called its context (or context window). Keeping relevant context is essential for coherent output, especially for long inputs. Currently, context window size goes up to ~1M tokens.
Notably, LLMs are stateless. When you chat or otherwise have a multi-step interaction with an LLM, the history of the interaction is only accumulated in the context window, not in the model itself. This highlights a couple of fundamental limitations:
- There is no persistence to your interactions with an LLM; any persistence has to be simulated by including previous input and/or output in the context window.
- The context window is finite and will eventually fill up, so there is an inherent limit on the complexity of interactions (and this is also why you can’t simply chuck your entire large code base into the LLM to be analysed).
During inference, LLMs rely on techniques like constrained decoding, which restricts what tokens can be chosen next, for the purpose of generating structured outputs (eg. JSON). Temperature is another decoding parameter which controls randomness in output generation. A low temperature makes outputs more deterministic, while a high temperature introduces more variety.
Enhancing the quality of inference
Since models only take input via their context window, all of the techniques in the inference phase amount to context stuffing, ie. choosing what information to include in the context to facilitate the generation of a useful output.
It turns out that LLMs can sometimes be nudged into producing better results by including something in the context to induce them to detail reasoning steps in the output. This can be as simple as adding “Let’s think step by step” to the prompt, or it can be providing an example of reasoning for a similar problem. This technique guides the model to include step-by-step “thinking” in the output, mimicking human analytical processes (referred to as reasoning). Since there is more output generated, it means that higher output quality comes at the cost of more computation during inference.
The models which include the extra reasoning output are sometimes called Large Reasoning Models (LRMs).
Another technique is called retrieval-augmented generation (RAG) which means somehow retrieving information from external sources (for example, a web search or an internal document store) and incorporating it into the context. The nature of training means that models have a fixed cutoff date for the training data, so RAG is also a useful way of incorporating more recent information without going to the trouble of repeated fine-tuning.
The various training and inference steps are shown in the following diagram.
Modes of generative AI
Since foundation models are multimodal, LLMs can process a variety of input types and correspondingly generate a variety of output types. This includes images, audio, and video. There are other types of generative AI models such as diffusion models used for image generation (eg. Stable Diffusion). Applications include text-to-speech, image generation and editing, music generation, and 3D model generation.
AGI
AI hype includes frequent references to AGI (artificial general intelligence) which is an ill-defined term that’s vaguely meant to denote a system that can match or exceed human performance on all types of cognitive tasks. There is no solid evidence that this is imminent or even achievable at all.
Measuring performance
Finally, evals or eval refers to structured evaluation tests that assess various aspects of model performance (eg. reasoning, factual accuracy, bias). These are used to compare models.
Benchmarks and evals come with a lot of caveats, in particular leakage of benchmark data into model training datasets (which may inflate scores), prompt sensitivity (minor changes to prompts can produce drastically different results), and in general the difficulty of thorough evaluation given the nature of generative AI models.
Risks and ethical concerns
There is a range of risks in relying on generative AI. This includes hallucinations which are factually incorrect or nonsensical outputs that look plausible on the surface. Additionally, you need to be mindful of security issues, biases, poor quality outputs as well as risks to the operator such as loss of skill.
There is also a range of ethical concerns to consider, in particular:
- the provenance of training data and the lack of compensation to the authors
- the potential effects of AI on employment and society more broadly
- priorities around resource and energy use.
Operational infrastructure
Some specialised knowledge is required to train and operate LLMs (manage training data, deploy models, monitoring performance etc.). This is referred to as LLMOps, a subset of MLOps.
Agents and other development tools
In general, an agent is a piece of software that augments the LLM with additional functionality in order to perform some kind of tasks (at minimum, information retrieval from an external source).
The agent may be making LLM requests in a loop. Commonly, additional components of an agent are:
- a planning/orchestrating module
- memory mechanism to repopulate context across interactions
- integration with external tools to retrieve information or perform actions.
Basic agent architecture is shown below:
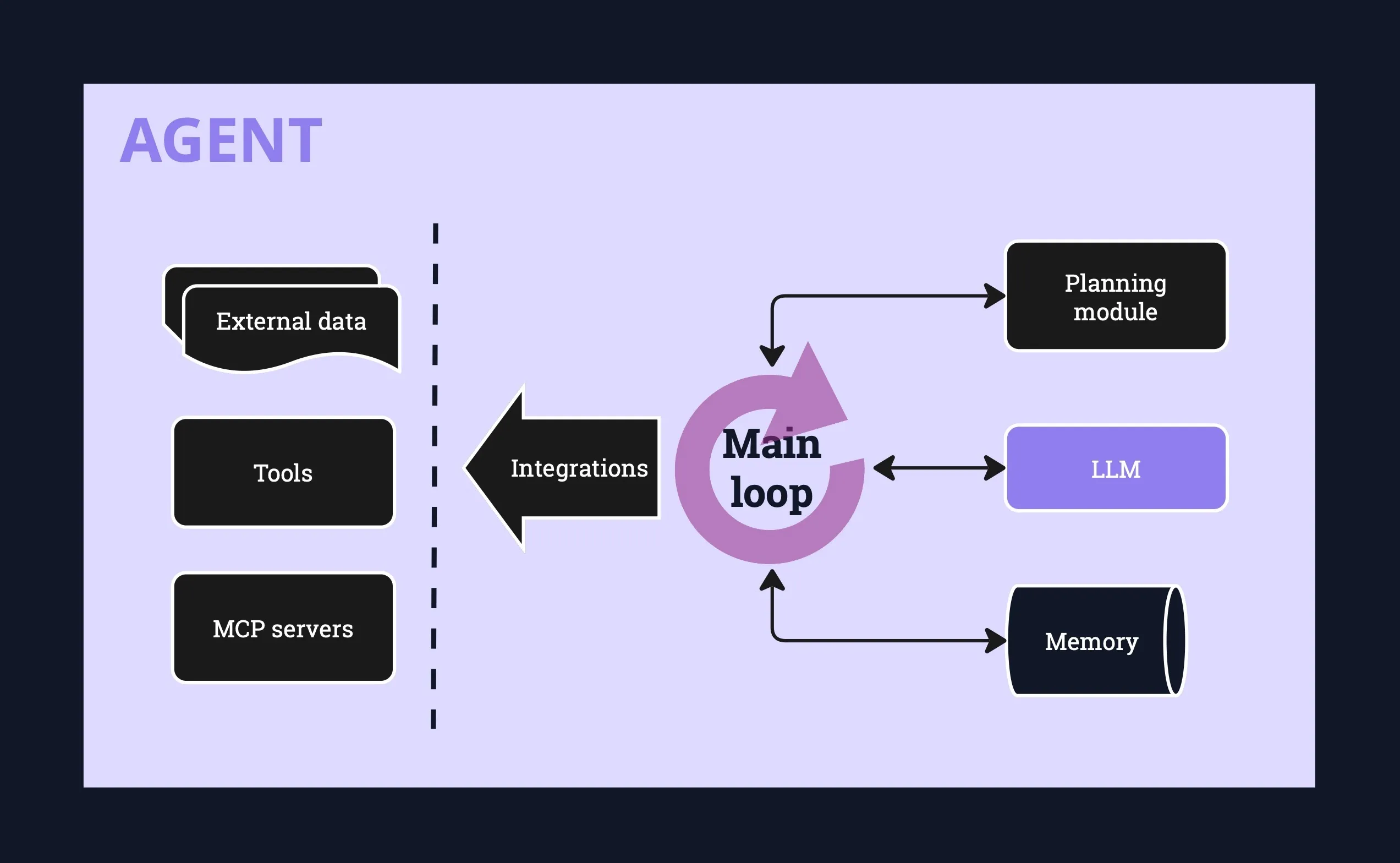
Integrations with external tools take the form of function calling or more recently the Model Context Protocol (MCP), which allow the agent to retrieve instructions to execute a call from structured LLM output. The description of available functions or MCP servers is passed to the LLM via the context window. Agents might also be integrated with external data storage in order to retrieve information that also goes into the context window.
For the purposes of understanding the direction of agent development for software engineering, it’s worth doing a microscopic history retrospective:
- At first, we had the chat interface to LLMs where we could copy and paste bits of code.
- Quickly, the chat moved into the IDE and was supplemented with code autocompletion.
- The next step was to allow LLMs the ability to interact with the computer (execute programs, perform web searches etc.) and make changes to the filesystem as well as perform multi-file edits across the code base. The idea here is both to allow the provision of constraints and checks on LLM output, as well as the ability to give LLMs more substantial tasks.
- Now, providers are aiming to give agents more autonomy by allowing the user to kick off multiple tasks in parallel and have agent instances churn away on them in the background (or elsewhere, eg. on GitHub).
Besides agents that generate code, LLMs are being applied to other tasks such as code reviews, generating architecture overviews, generating commit messages, debugging, and so on.
Attempts to use all these tools to generate working software (mostly) without reviewing or manually modifying generated code are termed vibecoding. Vibecoding is sometimes used in a more general way to refer to any AI-assisted coding.
Going deeper

Some more reading and watching on LLMs: